2019年6月6日讨论班报告
各位老师,同学:
时间:6月6日讨论班 9:00-10:30
地点:教学楼5-308
报告内容:
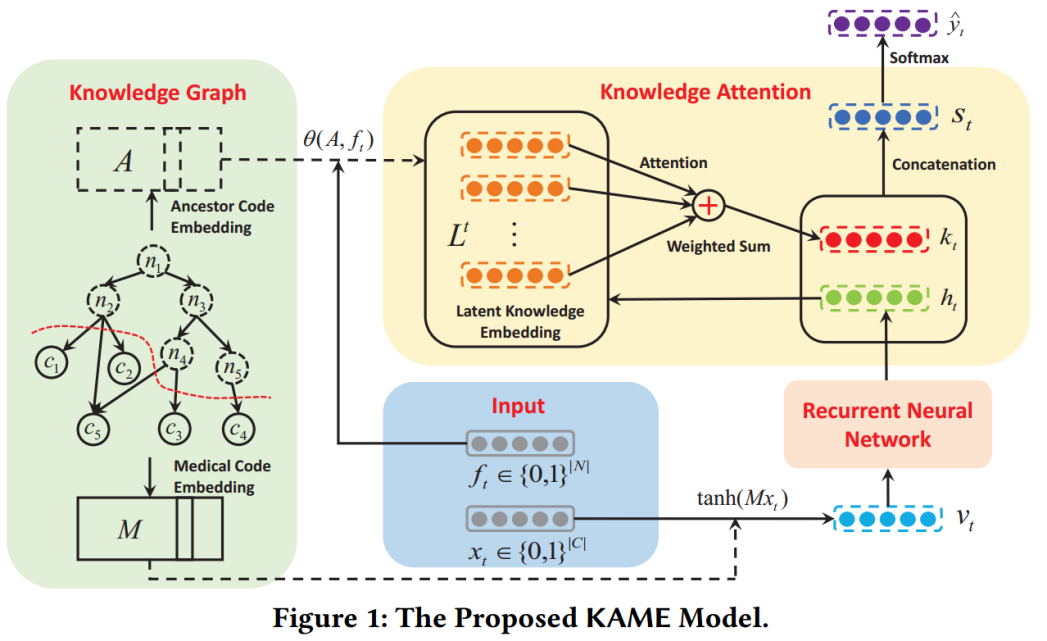
孙振超 KAME: Knowledge-based Attention Models for Diagnosis Prediction in Healthcar
诊断预测任务的目标是从其历史EHR记录中预测患者未来的健康情况。诊断预测中最重要、最具挑战性的问题是设计出准确、稳健且可解释的预测模型。现有的工作通常采用具有Attention机制的RNN来解决此类问题,但是这些方法需要使用大量的数据。为了在数据不足的情况下获得良好的性能,有研究者提出了基于图的注意力模型。但是,当训练数据足够时,与普通的基于Attention的模型相比,这些图模型不会提供任何性能改善。为了解决这些问题,我们提出了一种端到端的模型:KAME,用于预测患者未来健康信息。KAME不仅可以从知识图谱中学习节点的有效词向量(embedding),而且能够利用所提出的knowledge attention机制,利用一般知识来提高预测精度。通过学习到的attention,KAME可以帮助解释图中每条知识的重要性。在三个数据集的实验结果表明,与现有技术方法相比,所提出的KAME显着提高了预测性能,保证了数据充足和不充分的稳健性,并学习了可解释的疾病表征。
姜涛 CA-RNN: Using Context-Aligned Recurrent Neural Networks for Modeling Sentence Similarity
近年来,递归神经网络(RNNs)在句子相似度建模方面表现出良好的性能。大多数RNNs都是基于当前句子对hidden state 进行建模。但是在生成 hidden state 的过程中,对来自另一个句子的上下文信息却没有很好的研究。本文提出了一种基于上下文对齐的RNN (CA-RNN)模型,该模型将对齐后的词的上下文信息整合到一个句子对中,用于内部 hidden state的生成。具体来说,我们首先执行单词对齐检测来识别两个句子中对齐的单词。然后,我们提出了一种上下文对齐控制机制,并将其嵌入到我们的模型中,以自动吸收对齐的单词上下文来进行hidden state更新。在TREC-QA和WikiQA这三个基准数据集上进行了测试,结果表明了本文模型的优越性。特别是,我们在TREC-QA和WikiQA上达到了一个最新的性能表现。此外,我们的模型在MSRP数据集上,即使不比最近基于神经网络方法更好,至少也可以与之媲美。
下周报告人 弭娜,张忠凯




