WWW2020论文解读:A Category-Aware Deep Model for Successive POI Recommendation on Sparse Check-in Data
Fuqiang Yu, Lizhen Cui, Wei Guo, Xudong Lu, Qingzhong Li and Hua Lu
软件学院&山东大学-南洋理工大学人工智能国际联合研究院 (Joint SDU-NTU Centre for Artificial Intelligence Research,简称C-FAIR)
山东大学
本文对WWW2020的Oral长文《A Category-Aware Deep Model for Successive POI Recommendation on Sparse Check-in Data》进行了要点解读。
大规模POI签到数据的积累,使得连续的兴趣点(POI)推荐热度越来越高。然而,现有的连续POI推荐方法仅预测用户下一步将去哪里,而忽略了何时会发生此行为。因此,本文专注于预测用户将在接下来的24小时内访问的POI。同时,此工作着重攻克以下两个难点。
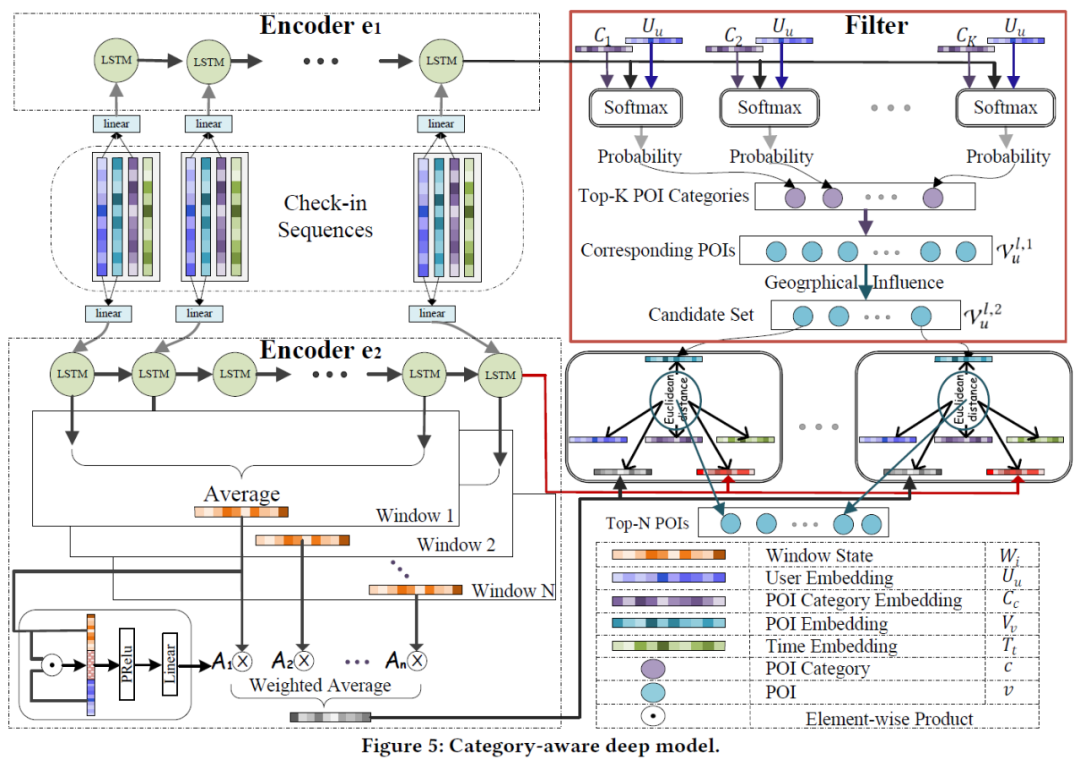
数据稀疏性:由于签到数据非常稀疏,要准确地捕获时间模式中的用户偏好非常具有挑战性。签入数据的稀疏性,是由于每个用户都以有限数量的POI签入,反之亦然。 例如,从数据集NYC中随机选择6个用户和60个POI,并在Figure.1中绘制了user-POI矩阵,颜色的强度指示用户访问POI的频率。显然,user-POI矩阵的密度相当低。 具体来说,在Foursquare的纽约(NYC)和东京(TKY)两个数据集中,数据稀疏性分别高达99.51%和99.58%。 对于稀疏的签入数据,准确地捕获用户的偏好并向用户推荐POI以供用户在随后的几个小时内访问非常困难。针对此问题,本文提出了一个类别感知型深度模型CatDM(Figure.5),该模型结合了POI类别和地理位置的影响力,以减少搜索空间来克服数据稀疏性。

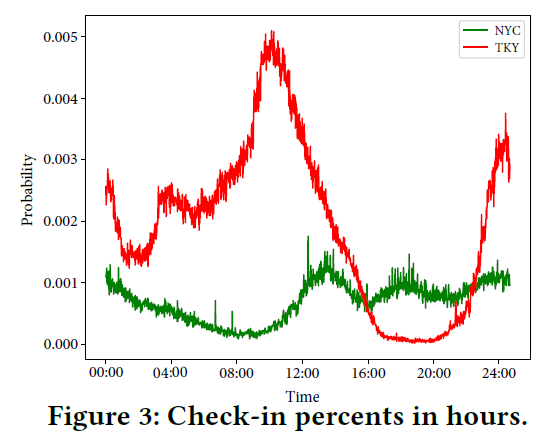
用户行为模式:本文设计了两个基于LSTM的深度编码器,以对时间序列数据进行建模。第一个编码器用来捕获用户对POI类别的偏好,而第二个编码器用来捕捉用户对POI的偏好。考虑到用户行为在一天中不同时间段的时钟影响,例如,Figure.3展示了NYC和TKY数据集上人们在一天中不同时间点的访问POI行为。显然,人们在不同的时间点会有不同的POI访问行为或偏好。例如:用户更可能在午餐或晚餐时间对餐厅感兴趣。因此,在其他时间向用户推荐餐厅的意义较小。本文使用时钟影响来捕获这种更精细的时间粒度上的用户兴趣,本文在第二个编码器中将每个用户的签到行为分为不同的时间窗口,并为每个窗口设计个性化的attention机制,以方便CatDM利用和捕获用户行为的时间模式。此外,为了对生成的候选集进行排序,本文考虑了四个特定的依存关系:(1)用户-POI,(2)用户-POI类别,(3)POI-时间,(4)POI-用户当前偏好。
本文在两个大型真实数据集(NYC和TKY)上进行了广泛的实验。实验结果表明,对于在稀疏签到数据上的连续POI推荐问题, CatDM效果优于其他模型。